
Remember when Spotify was granted a patent for personality tracking technology, and how unsettling it was?
Published in October 2020, the filing explained that behavioural variables, such as a user’s mood, their favourite genre of music, or their demographic could all prospectively “correspond to different personality traits of a user”.
Spotify suggested that it could promote personalized content – presumably audio advertising content, but also perhaps music and podcast content – to users based on the personality traits it detected in them.
Now, according to details published in a new US Spotify patent, the company wants to use technology to get even deeper into its users’ heads, by using speech recognition to determine their “emotional state, gender, age, or accent” – attributes that can then be used to recommend content.
The new patent, entitled “Identification of taste attributes from an audio signal”, which you can read in full here, was filed in February 2018 and granted on January 12 this year.
According to the filing, SPOT’s new patent covers a “method for processing a provided audio signal that includes speech content and background noise” and then “identifying playable content, based on the processed audio signal content.”
Spotify explains that “it is common for a media streaming application to include features that provide personalized media recommendations to a user”.
An existing approach to identifying what type content a user should be recommended, notes the filing, is to ask them to provide “basic information such as gender or age”.
“A more basic approach might simply categorize [a user’s] emotion into happy, angry, afraid, sad or neutral… Prosaic information (e.g. intonation, stress, rhythm and the like of units of speech) can be combined and integrated with acoustic information within a hidden Markov model architecture, which allows one to make observations at a rate appropriate for the phenomena to be modeled.”
Spotify Patent
Continues the filing: “The user is then further asked to provide additional information to narrow down the number even further. In one example, the user is pushed to a decision tree including, e.g., artists or shows that the user likes, and fills in or selects options to further fine-tune the system’s identification of their tastes”.
This method is not efficient enough, argues Spotify, because it requires users “to tediously input answers to multiple queries in order for the system to identify the user’s tastes”.
Spotify’s solution? Collect “taste attributes of a user”, using speech recognition technology.
At one point, the patent suggests that obtaining “intonation, stress, rhythm and the likes of units of speech” could be combined with “acoustic information within a hidden Markov model architecture” so that Spotify’s app could categorize a user’s mood as “happy, angry, sad or neutral”.
How Spotify intends on doing this, according to the patent, is by retrieving content metadata from a user’s voice and/or from background noise.
In addition to determining attributes such as age, gender and accent, that content metadata could indicate “an emotional state of a speaker providing the voice”.
Environmental metadata could indicate a specific background noises such as “sounds from vehicles on a street, other people talking, birds chirping, printers printing, and so on” (see below).
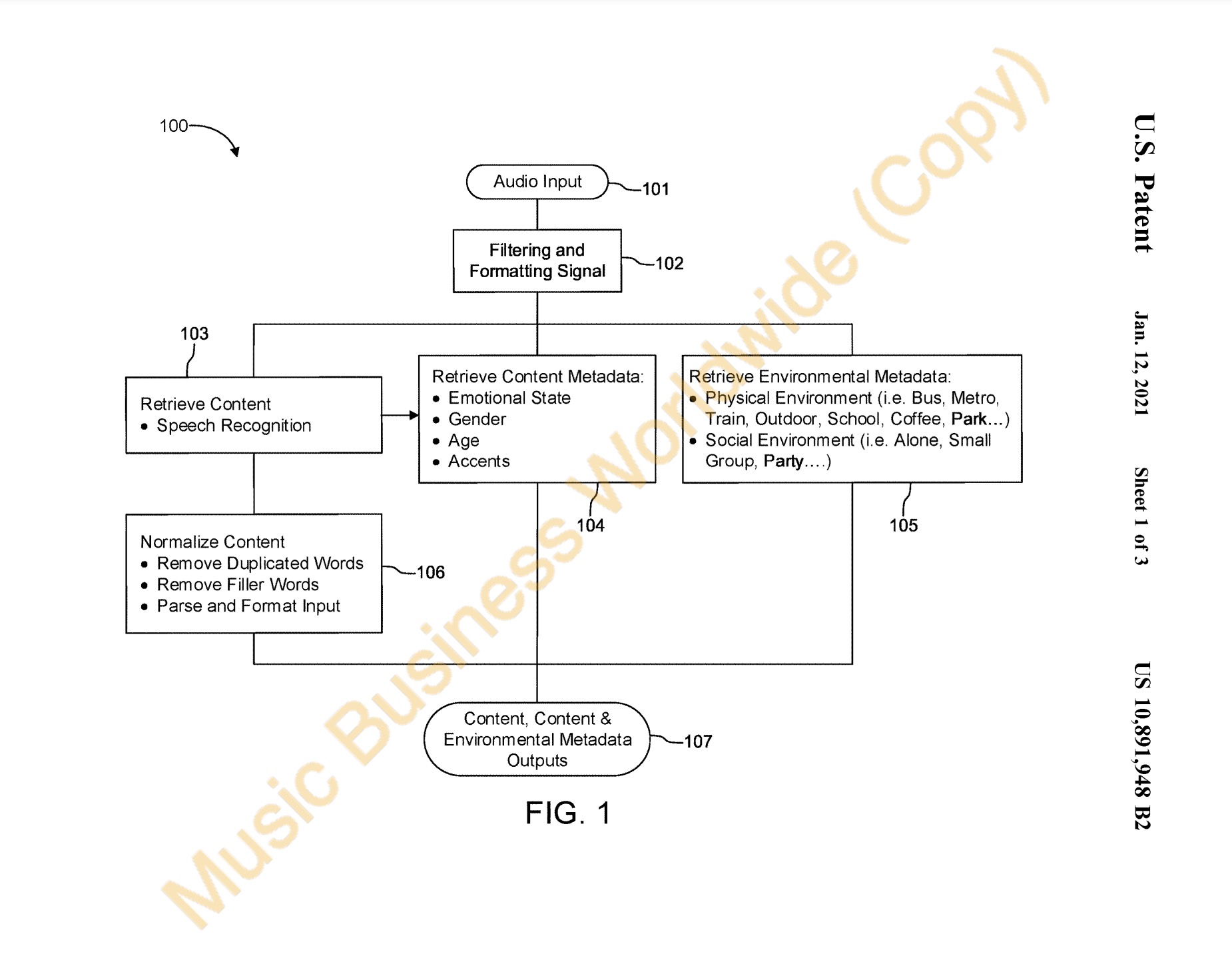
By identifying a user’s emotional state from the sound of their speech, the filing explains, a user’s emotions could be classified using approaches such as the slightly complex Parrott’s emotional framework which “uses a tree-structured list of emotions with levels”.
As mentioned, another “more basic approach” suggested in the filing is to simply determine a user’s emotional state from their speech as “happy, angry, afraid, sad or neutral”.
“For example, prosodic information (e.g., intonation, stress, rhythm and the like of units of speech) can be combined and integrated with acoustic information within a hidden Markov model architecture,” adds the filing.
“Using this architecture, that prosodic information allows the emotional state of a speaker to be detected and categorized”.
Elsewhere, explains the filing, age can be “roughly” determined based on “a combination of vocal tract length and pitch”.
Additionally, a “gender recognition system can be used to extract the gender related information from a speech signal and represent it by a set of vectors called a feature”. Features such as power spectrum density or frequency at maximum power can carry speaker information.
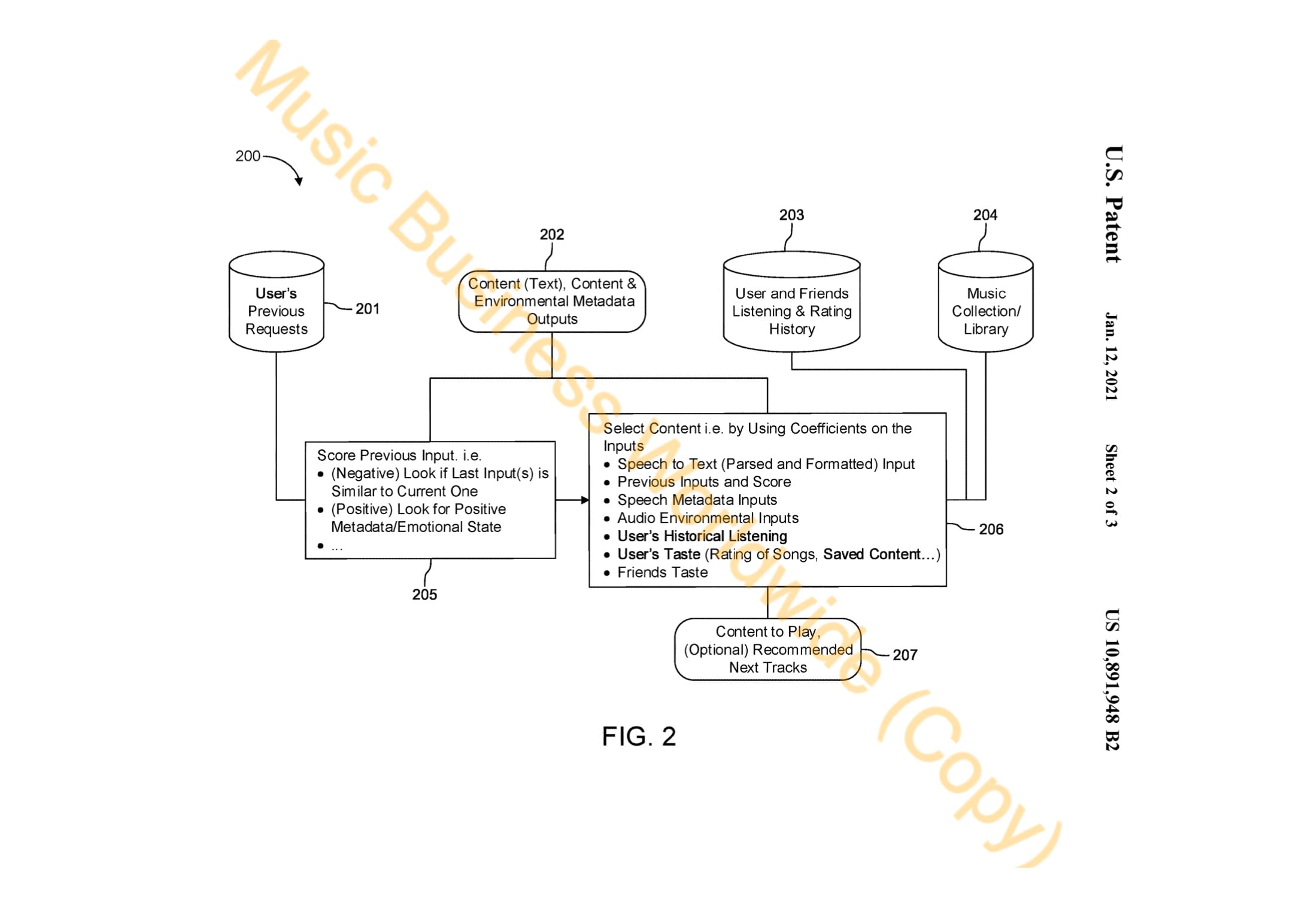
As shown in Fig. 2 above, content is recommended to the listener once all of this metadata has been extracted and analyzed alongside a listener’s “previous requests” their “listening and rating history” and “links to associated profiles such as those of the user’s friends or colleagues”, as well as “the user’s existing music collection and/or library”.
“In one example, the output might simply be to play the next content,” explains the filing.
“In another example, the output might be a recommendation on a visual display.
“Accordingly, in one aspect, the output is audio output of music corresponding to the preferences. In another example aspect, the output is a display of recommended next music tracks corresponding to the preferences”.
This is the latest in a series of US patents granted to Spotify in recent months.
MBW discovered in September, for example, that the platform had been granted a patent for a new karaoke-like feature that allows users to “overlay a music track with their own vocals”.
In November, the company was granted a patent that suggests the company is working on geo-targeted advertising, using 3D audio.Music Business Worldwide