There’s an AI music wave sweeping across big tech.
In January, Google announced a language model called MusicLM that can generate new music from text prompts, making it publicly available last month.
Last weekend, Facebook parent company Meta released its own text-to-music AI generator called MusicGen, which the company says has been trained on 20,000 hours of licensed music, including 10,000 “high-quality” tracks and 390,000 instrument-only tracks from ShutterStock and Pond5.
Meta and Google aren’t the only giants of the tech and computing world conducting research in the AI music space, however.
Rival Microsoft runs a vast research project dedicated to AI Music. It’s called ‘Muzic’, and its researchers’ work ranges from AI-powered text to music generation, lyric generation, Lyric-to-Melody Generation, songwriting and more.
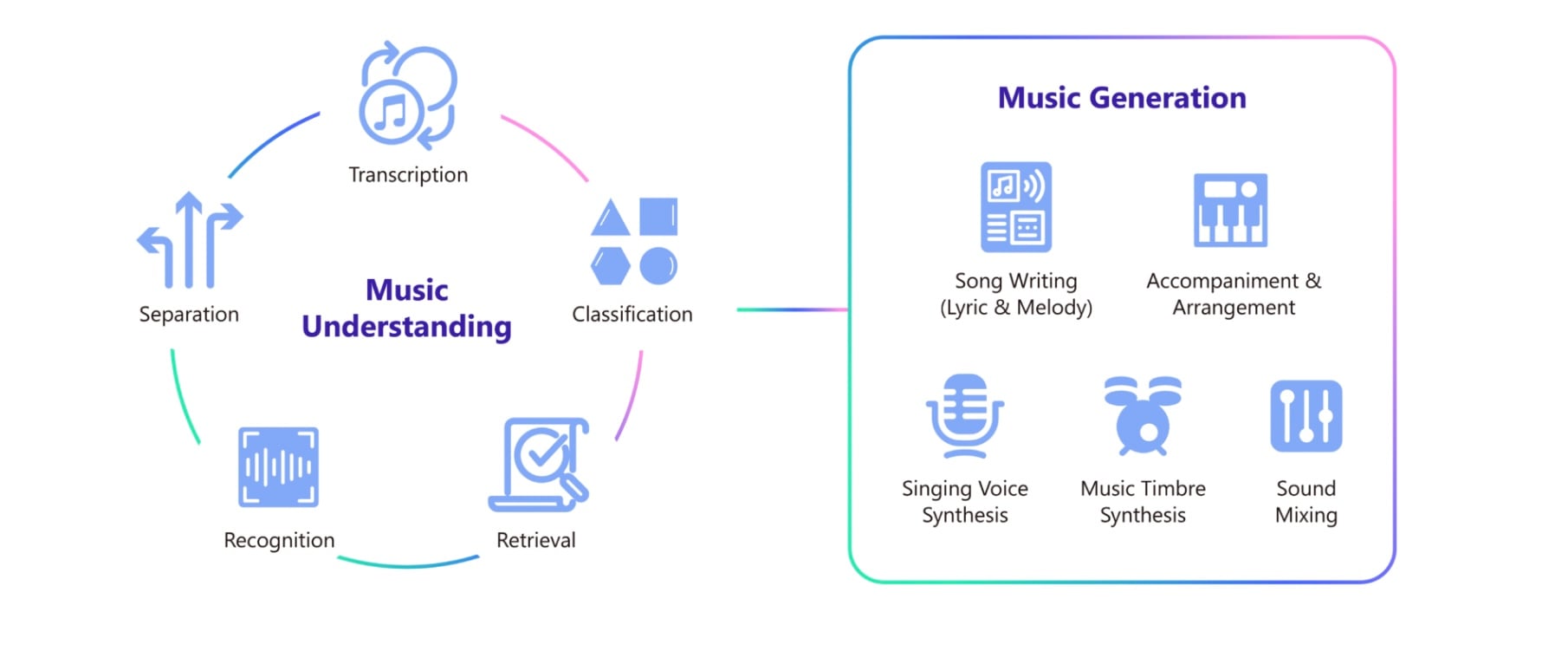
According to Microsoft, ‘Muzic’ is a “project on AI music that empowers music understanding and generation with deep learning and artificial intelligence”.
You can see the diagram from their landing page below:
Muzic, which was established in 2019, is just one of the projects that sit under ‘The Deep and Reinforcement Learning Group’ at Microsoft Research Asia (MSR Asia) in China.
Microsoft Research Asia is described as “a world-class research lab” with locations in Beijing and Shanghai. The tech giant says that MSR Asia, which was established in 1998, “conducts basic and applied research in areas central to Microsoft’s long-term strategy and future computing vision”.
In addition to its AI Music research, the ‘The Deep and Reinforcement Learning Group’ is running projects on neural network-based text-to-speech models, Neural Machine Translation, and more.
Just to reiterate, ‘Muzic’ has already produced a fairly large body of work in the field of AI Music.
Here are some of its standout projects:
1) DeepRapper
Of all the projects in the works at Muzic, this one might make a few music rightsholders spit out their coffee.
In 2021, Muzic researchers developed an AI-powered ‘rap generator’ called DeepRapper.
The paper outlining the development and experimentation of the text-based model claims that, “to [the researchers’] knowledge, DeepRapper is the first [AI] system to generate rap with both rhymes and rhythms”.
They add: “Both objective and subjective evaluations demonstrate that DeepRapper generates creative and high-quality raps.” They released the code for DeepRapper on GitHub, which you can find here.
According to the paper: “Previous works for rap generation focused on rhyming lyrics but ignored rhythmic beats, which are important for rap performance. In this paper, we develop DeepRapper, a Transformer-based rap generation system that can model both rhymes and rhythms.”
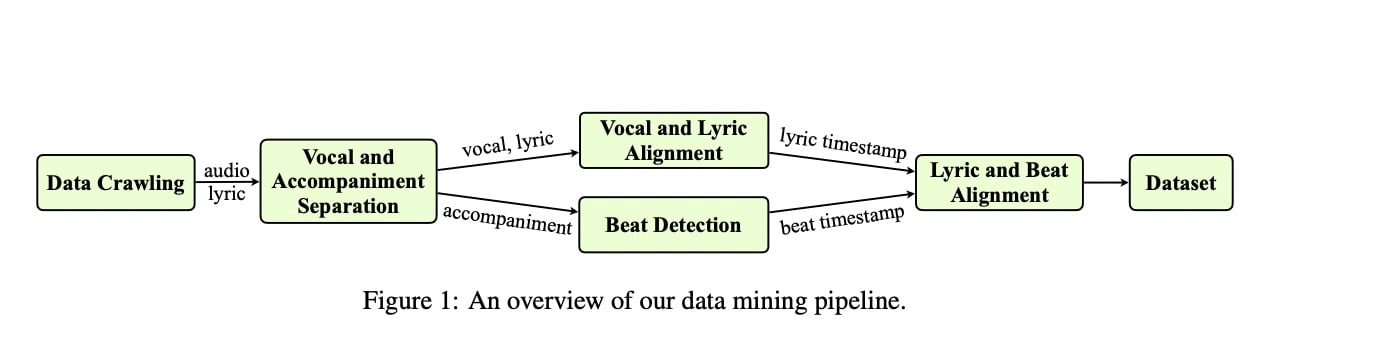
The researchers explain that to build the DeepRapper system, “since there is no available rap dataset with rhythmic beats,” they developed what they call “a data mining pipeline to collect a largescale rap dataset, which includes a large number of rap songs with aligned lyrics and rhythmic beats”.
Second, they designed a so-called “transformer-based autoregressive language model” which “carefully models” rhymes and rhythms.
“To mine a large-scale rap dataset, we first crawl a large amount of rap songs with both lyrics and singing audios from the Web.”
They give more details later in the paper about how they designed “a data mining pipeline [to] collect a large-scale rap dataset for rhythm modeling” (see diagram below).
They explain: “To mine a large-scale rap dataset, we first crawl a large amount of rap songs with both lyrics and singing audios from the Web.
“To ensure the lyric and audio can be aligned in the sentence level which is beneficial for our later word-level beat alignment, we also crawl the start and end time of each lyric sentence corresponding to the audio.”
Their data mining for the research didn’t stop there. According to the research paper, they also used their “data mining pipeline to collect another two datasets: 1) non-rap songs with aligned beats, which can be larger than rap dataset since non-rap songs are more general than rap songs; 2) pure lyrics, which can be even larger than non-rap songs”.
The DeepRapper model was trained on the above two datasets during the “pre-training stage”. They explain that they then “fine-tune our pre-trained model on the rap songs with aligned beats”.
The researchers conclude that “both objective and subjective evaluations demonstrate that DeepRapper generates high-quality raps with good rhymes and rhythms.”
They randomly generated 5,000 samples, some of which you can see for yourself, here.
These samples were generated in Mandarin, and the researchers used Google Translate to provide the English translations.
(The very first lyric of the presented samples? “We have yellow skin with hot blood/Let this song come to the night of medical insomnia.”)
The paper concludes that “thanks to the design of DeepRapper, we can further build another rap singing system to sing out the raps according to the rhymes and rhythms, which we leave as future work”.
It’s now fairly well known that generative AI models are trained on vast sets of data, often scraped from the internet.
This is a fact that’s not particularly liked by music rightsholders, due to the risk of infringement by those AI models of copyrighted music. What’s interesting here is the Microsoft team’s candid explanation of how DeepRapper’s data is obtained, albeit for research purposes.
Interestingly, Microsoft’s research around rhymes and rapping appears to be a global effort.
In addition to the DeepRapper model detailed above, developed by the Muzic team in China, Microsoft also has a US patent, which appears to be an entirely separate tool from DeepRapper, for a “Voice Synthesized Participatory Rhyming Chat Bot”.
This ‘rap-bot’ technology was invented by another group of Microsoft researchers based in the US. The patent was granted in April 2021.
The filing, obtained by MBW, lists a bunch of different uses for the chatbot, for example, that it “may support rap battles” and “participate in the music creation process in a social way”.
A few other models worth highlighting that the Microsoft researchers in Asia have worked on revolve around singing voice synthesis, aka, Ai-powered human voice-mimicking technology.
We’ve written about this topic a few times recently on MBW. HYBE, for example, acquired a fake voice AI company called Supertone last year in a deal worth around $32 million, following an initial investment in the startup in February 2021.
Supertone generated global media attention in January 2021 with its so-called Singing Voice Synthesis (SVS) technology. The company’s tech was recently used on a multilingual track released by HYBE virtual artist MIDNATT.
Meanwhile, in November, Tencent Music Entertainment (TME) said that it had created and released over 1,000 tracks containing vocals created by AI tech that mimics the human voice and one of these tracks has already surpassed 100 million streams.
In the wider arena of AI-powered voice mimicry, we also reported on the controversial fake Drake track called heart on my sleeve, featuring AI-synthesised AI vocals copying the voices of Drake and The Weeknd.
The research team at Muzic have written three papers on singing voice synthesis.
“The results demonstrate that with the singing data purely mined from the Web, DeepSinger can synthesize high-quality singing voices in terms of both pitch accuracy and voice naturalness.”
One of the models they designed is titled ‘DeepSinger: Singing Voice Synthesis with Data Mined From the Web’. The accompanying paper for the model details “a multi-lingual multi-singer singing voice synthesis (SVS) system, which is built from scratch using singing training data mined from music websites”.
According to the paper, “the pipeline of DeepSinger consists of several steps, including data crawling, singing and accompaniment separation, lyrics-to-singing alignment, data filtration, and singing modeling”.
The data mining step, according to the paper, included “data crawling” of “popular songs of top singers in multiple languages from a music website”.
They explain further that “we build the lyrics-to-singing alignment model based on automatic speech recognition to extract the duration of each phoneme in lyrics starting from coarse-grained sentence level to finegrained phoneme level”.
According to the researchers, their DeepSinger tool “has several advantages over previous SVS systems,” including that, “to the best of [their] knowledge, it is the first SVS system that directly mines training data from music websites” and “without any high-quality singing data recorded by human.”
The researchers write in the paper that they evaluated DeepSinger on a “mined singing dataset that consists of about 92 hours data from 89 singers on three languages (Chinese, Cantonese and English)”‘.
They continue: “The results demonstrate that with the singing data purely mined from the Web, DeepSinger can synthesize high-quality singing voices in terms of both pitch accuracy and voice naturalness.”
You can hear samples generated by the model, here.
3) MuseCoCo
The most recent of those projects, details of which were only just published on May 31, is an AI-powered text-to-symbolic music generator.
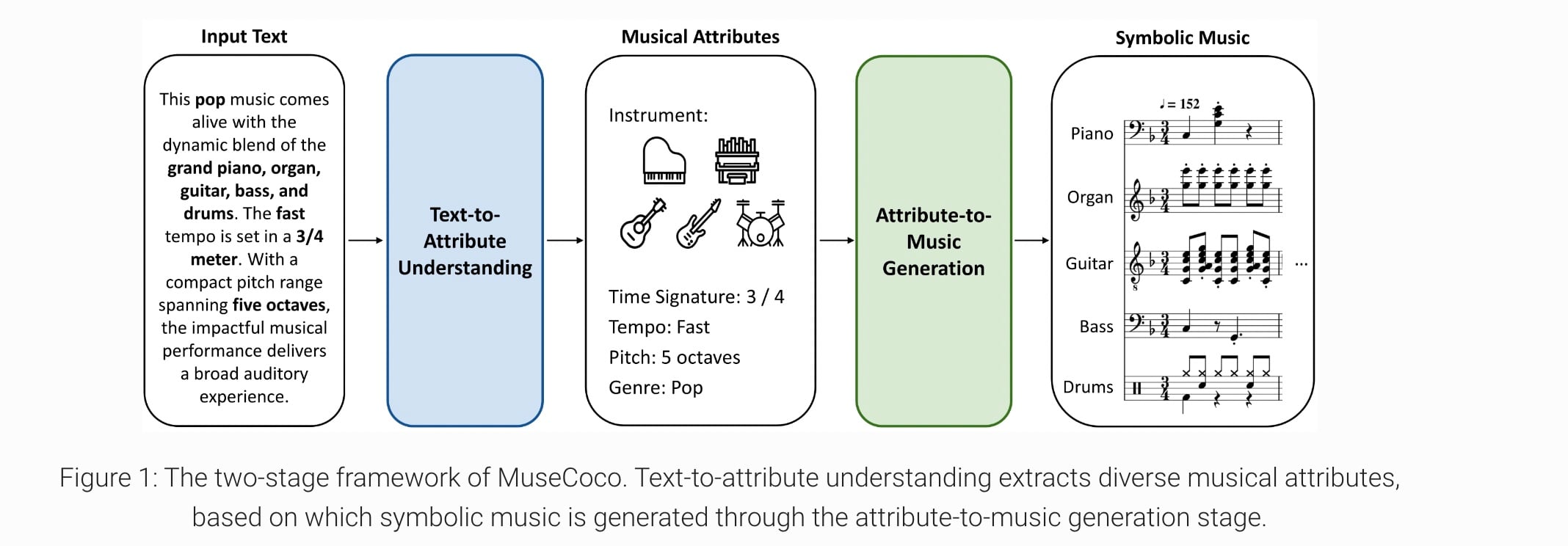
‘MuseCoCo‘, which stands for ‘Music Composition Copilot’ generates “symbolic music” (e.g., MIDI format, but not audio) from text prompts (see below).
The researchers say that they used notation platform MuseScore to export mp3 files of what the music sounds like for reference.
They have published a bunch of samples here demonstrating the audio results after inputting text prompts of various lengths and complexity into the composition tool, alongside comparisons from other language models.
Microsoft’s Muzic claims that the model “empowers musicians to generate music directly from given text descriptions, offering a significant improvement in efficiency compared to creating music entirely from scratch”.
A paper, which is still under review, has also been made public alongside the results of the research.
According to the researchers, their approach to text-to-music generation “breaks down the task into two stages” the first of which is “text-to-attribute understanding” and the second is the “attribute-to-music generation stage”.
In the ‘text-to-attribute understanding’ stage, the text is “synthesized and refined” by ChatGPT.
The paper claims, that “due to the two-stage design, MuseCoco can support multiple ways of controlling” the results.
It explains: “For instance, musicians with a strong knowledge of music can directly input attribute values into the second stage to generate compositions, while users without a musical background can rely on the first-stage model to convert their intuitive textual descriptions into professional attributes.
“Thus,” according to Muzic, “MuseCoco allows for a more inclusive and adaptable user experience than those systems that directly generate music from text descriptions.”
The paper also outlines what the mode was trained on. Remember, Meta’s MusicGen AI model, which can generate 12-second audio clips from a text prompt, was trained on 20,000 hours of licensed music.
According to Muzic’s researchers, “To train the attribute-to-music generation stage and evaluate our proposed method”, they collected an assortment of MIDI datasets from “online sources”.
They said that they “did the necessary data filtering to remove duplicated and poor-quality samples,” and were left with 947,659 MIDI samples.
One of those datasets is listed as the MetaMIDI Dataset (MMD), described as “a large-scale collection of 436,631 MIDI files and metadata.”
The MMD “contains artist and title metadata for 221,504 MIDI files, and genre metadata for 143,868 MIDI files, collected through [a] web-scraping process”.Music Business Worldwide